Ph.D. project: The multi-wavelength view of the AGN – star formation relation
I am happy to announce a new position to work on a Ph.D. project at the Sterrewacht Leiden / Leiden University
The multi-wavelength view of the AGN – star formation relation
One of the long-standing questions in astrophysical research is what exactly triggers the onset of Active Galactic Nuclei (AGNs). The aim of this project is (1) to study the nuclear star formation history in a well selected sample of nearby AGNs with exquisite data (VLT/X-SHOOTER spectra) and (2) to participate or lead pioneering efforts to study gas, dust and star formation in the parsec-scale environment of nearby actively accreting super-massive black holes using the upcoming infrared interferometer MATISSE on the VLTI.
Supervisors: Dr. Leonard Burtscher, Prof. Dr. Walter Jaffe
Promoter: Prof. Dr. Bernhard Brandl
Wieso brauchen wir den Science March auch in Deutschland?
Gestern Abend war ich (als einer der Organisatoren des Münchner Science March) im Gespräch mit einem Reporter für Bayern 5 Aktuell. Er sagte mir, dass er nur einen kurzen Bericht machen wolle und daher nur Platz für eine Frage/Antwort habe: “Wieso brauchen wir den Science March auch in Deutschland?
Was er damit meinte: Dominieren etwa in Deutschland schon “fake news”? Gibt es hier Schließungen von Universitäten und werden Wissenschaftler etwa auch hierzulande gegängelt wie in Ungarn oder der Türkei? Erhalten staatliche Agenturen Maulkörbe und verbreitet sogar die Regierung “alternative facts” wie in den USA?
Zum Glück lassen sich all diese Fragen mit einem klaren Nein beantworten.
Dennoch gibt es meiner Meinung nach aber auch hierzulande Gründe, um für die Wissenschaft zu marschieren. Hier sind ein paar:
- auch wenn “alternative facts” in Deutschland nicht dominieren, so gibt es sie hierzulande durchaus auch in der Politik und zwar quer durch die Parteienlandschaft:
- Mitte der 1990er Jahre hat die rot-grüne Regierung unter Gerhard Schröder den “Binnenkonsens” im Sozialgesetzbuch verankert. Demnach müssen Medikamente nicht mehr generell nach wissenschaftlichen Standards getestet werden, sondern lediglich nach den Standards, die in der jeweiligen “Therapie-Richtung” üblich sind. Das heißt im Klartext: wer ein neues (medizinisches) Medikament zulassen will, muss in aufwändigen klinischen Studien die Wirksamkeit des Medikaments nachweisen. Wer aber neue homöopathische Globuli, Bachblüten-Extrakte oder ähnliche Quacksalberei auf den Markt bringen möchte, darf sich auf seine “besondere Therapierichtung” berufen und muss lediglich nachweisen, dass das Medikament ungiftig ist. Dafür gibt es keinen vernünftigen Grund, aber insbesondere die Grünen wollten damals diverse esoterische Praktiken in den Katalog der Krankenkassen bekommen, was dann auch so geschehen ist. Bis heute zahlen viele große deutsche Krankenkassen für Mittelchen, für die nie ein Wirknachweis erbracht worden ist.
- nach mehreren Anläufen und Rückschlägen hat die CSU dieses Jahr die Einführung einer “Infrastrukturabgabe” (vulgo “Ausländer-Maut”) durchgesetzt. Sie hat zwar explizit auch zum Ziel, ausländische PKW-Halter zur Kasse zu bitten, begründet diesen “Racheakt” aber dann doch damit, dass zusätzliche Investitionen in die Verkehrsinfrastruktur notwendig seien. Nun sind sich die meisten Experten aber einig, dass durch diese Maut viel weniger Geld in die Bundeskasse fließt als von der CSU gedacht, womöglich wird sie gar ein Zuschuss-Geschäft. Damit fällt der wesentliche Nutzen dieser Maut weg. Das, freilich, wusste man schon seit langem, hat es aber ignoriert.
- ganz am rechten Rand des politischen Spektrums versucht die AfD auch mit der Leugnung wissenschaftlicher Erkenntnisse Stimmen zu fangen und schreibt in ihrem Parteiprogramm zum Thema Klimawandel, dass sich das Klima immer schon geändert habe, der Einfluss des Menschen nicht gesichert sei und mehr CO_2 im übrigen gut sei für das Wachstum von Pflanzen.
- Die Entwicklungen in der Türkei, in Ungarn, in Polen und in den Vereinigten Staaten haben auch gezeigt, wie schnell der Abbau von Demokratie und der damit verbundene Abbau freier Wissenschaft gehen kann. Es ist daher wichtig, immer wieder daran zu erinnern, wie wichtig freie Wissenschaft für unsere Demokratie und für unseren Wohlstand ist.
- Vor der Bundestagswahl im September sollten wir ganz konkret dazu aufrufen, die zur Wahl stehenden Parteien kritisch bezüglich ihrer Unterstützung von Wissenschaft zu beurteilen.
- und letztens sehe ich den Science March auch als Appell an Wissenschaftler, mehr zu tun, um die Bedeutung ihrer Wissenschaft einer breiteren Bevölkerungs-Schicht zugänglich zu machen. Wichtig ist dabei meines Erachtens nicht nur das Vermitteln von Ergebnissen, sondern auch die Diskussion der wissenschaftlichen Methode. Wir müssen stärker aufzeigen, wie rigoros Ergebnisse hinterfragt und geprüft werden und dadurch klar machen, weshalb wissenschaftliche Ergebnisse so viel belastbarer sind als Meinungen und Gefühle.
Rescue wrongly encoded e-mail attachment
Due to the long heritage of its underlying transport protocol SMTP, e-mail messages are still base64 encoded. This ensures that binary attachments (such as PDFs or zip files) are converted into the 7-bit ASCII character set [a-zA-Z0-9+/] that the SMTP protocol knows how to handle. The character `=` is used to terminate the so encoded string. The raw content of the attachment may look like this:
--Apple-Mail=_03A23B16-D748-4835-8340-CB928700DB3D Content-Disposition: inline; filename="spe1618_v4_doors_20161107.pdf" Content-Type: application/pdf; x-unix-mode=0644; name="spe1618_v4_doors_20161107.pdf" Content-Transfer-Encoding: base64 JVBERi0xLjQNCiW1tbW1DQoxIDAgb2JqDQo8PC9UeXBlL0NhdGFsb2cvUGFnZXMgMiAwIFIvTGFu Zyhlbi1HQikgL1N0cnVjdFRyZWVSb290IDMzOSAwIFIvTWFya0luZm88PC9NYXJrZWQgdHJ1ZT4+ [...] Pj4NCnN0YXJ0eHJlZg0KMjU5NTg4NQ0KJSVFT0Y=
Usually your e-mail client handles the decoding for you and all you see is a little icon, e.g. of a PDF document, which you can double-click to open the attachment. Sometimes it happens, however, that your e-mail client fails to properly decode this string and then you cannot open the attachment. In this case, simply save the long string “JVBE…FT0Y=” to a text file, say file.txt and then decode this using this shell command:
cat text.txt | base64 --decode > text.pdf
Hike to Mount Cardigan (New Hampshire, USA)
Yesterday, I hiked up Mount Cardigan, a rocky hill in Western New Hampshire, USA, together with a group of astronomers visiting the Dartmouth AGN workshop Hidden Monsters. Despite the bad weather forecast, we were lucky and didn’t get wet. Even better, we had a fantastic view from the bare-rock summit, standing in the midst of clouds passing by. Here are some impressions:















A time lapse video of a couple of astronomers crawling up the mountain:
And another one with some changing-look cloud cover:
And, finally, here is the GPS track of the hike:
http://my.viewranger.com/track/widget/3250807?locale=en&m=miles
Quite exhausting. Not so much the hike, but all the digital post-processing… 🙂
Solving BibDesk crashes
BibDesk is a great tool to manage your academic references (i.e. papers, books and other publications). Unfortunately the latest version (1.6.5) is crashing quite frequently, at least under Mac OS X 10.11.4. But the problem seems to be easily solvable (as described on the bibdesk mailing list) by changing or adding one parameter in the preferences.
Close BibDesk and open the preference file, i.e.
~/Library/Preferences/edu.ucsd.cs.mmccrack.bibdesk.plist
with a text editor, search for the key
FVWebIconMaximumNumberOfWebViews
and change its value to 0. In case this key is missing in your preference file (like it was the case on my machine), simply add it to the end of the file (it will re-arrange itself in the right way after re-opening the application), i.e. add
<key>FVWebIconMaximumNumberOfWebViews</key> <integer>0</integer>
For me this seems to have fixed the crashes.
Can you see the CMB in your analog TV?
For a public outreach talk I wanted to start with the importance of the Cosmic Microwave Background (CMB) for our understanding of the evolution of the universe. Then I remembered this anecdote that you can “see” the CMB radiation in the noise of your analog TV (if you still have one) and started wondering if that is actually true…

On the web there are several sources claiming that 1% of the noise between the channels of your TV programme are CMB, but I couldn’t find any actual calculation. So I tried my own.
Since I’m not an antenna expert and couldn’t immediately find some meaningful numbers for the radiation for analog terrestrial TV, I used this to come up with an order of magnitude number:
The old analog sender on top of mount Wendelstein in Upper Bavaria radiated at 0.4 kW in channel 48 according to the Wikipedia page. Channel 48 is at about 680 MHz and has a bandwidth of about 8 Mhz. This sender was apparently only used to broadcast to Bayrischzell which is about 2 km away. The sender had a round radiation pattern, i.e. it radiated in all directions, but only in one plane. However, since the town of Bayrischzell has a finite length, the half-power beam-width cannot have been too small. I assume here an H/R of ~ 0.2, i.e. at 2 km distance the half-power beam-width should be ~ 400m (i.e. illuminating an area of 5e6 m^2 at that distance). This is of course only a crude estimate, but for an order of magnitude calculation it should be OK. The specific flux received in Bayrischzell from this sender is thus
0.4 kW / (5e6 m^2 * 8e6 Hz) = 1e-11 W(m^2 Hz) or about 1e15 Jansky (in radio astronomers’ units)

OK, now let’s look at the specific flux of the CMB. This is easy, we just need to substitute proper values (2.7 K, 680 MHz) in the Planck equation and arrive at a specific flux of about 5.4e5 Jansky at the frequency used for the local TV station.
Now we need to compare this not to the signal strength estimated above, but to the estimated noise level of a typical analog TV receiver system. This is a bit tricky, but typical carrier-to-noise ratios (CNR) should be of some help. The carrier-to-noise ratio is the signal-to-noise ratio of a modulated signal. I didn’t find any recommended CNR values for terrestrial analog TV, but other CNR values for TV might give some guidance. In an article published with the Society of Cable Telecommunications Engineers, this guidance is given:
The FCC’s minimum CNR is 43 dB, which, in my opinion, is nowhere near good enough in today’s competitive environment. Indeed, most cable operators have company specs for end-of- line CNR somewhere in the mid to high 40s, typically 46 to 49 dB.
The National Association of Broadcasters Engineering Handbook (p. 1755) has a similar statement:
Noise will become apparent in pictures as the carrier-to-noise ratio (CNR) approaches 43-44 dB […]; a good design target is 48-50 dB.
So let’s assume the sender on mount Wendelstein is calibrated such that is achieves a CNR of 50 dB for the terrestrial analog broadcasting of the local TV station in nearby Bayrischzell. This means the signal is a factor 100,000 (1e5) stronger than the noise.
In this case, the noise level in the TV is about 1e10 Jy or about 200.000 times larger than the CMB signal. So, if this calculation is correct, it seems unlikely that you would be able to see the CMB signal while searching for signal with your analog terrestrial TV.
Good Apple service / Weird iPhone mobile data behaviour
Recently my iPhone had fallen on the street and the sapphire protection glas of the iSight camera cracked. Pictures could still be taken and they looked OK, but stark contrasts would lead to artefacts. Also, the aluminium shell of the phone got a few bruises. A few days later I received a notice that my iPhone 6 Plus was part of a replacement programme. Now that’s lucky given the circumstances…
On 5 Feb, I went to the Apple store in the Munich Olympia-Einkaufszentrum (OEZ) to get the camera replaced. When they tested the iPhone, however, they found that my camera was actually OK and would not need replacement. But after showing them the cracked sapphire glas and the bruises on the shell, they agreed to swap — not just the camera — but the entire phone by a new one! I was really surprised by this level of service.
Mysterious heavy use of mobile data in “System Services > Documents & Sync”
After restoring the backup I made just before leaving to the OEZ, my brand-new iPhone behaved very much like the old one and all data had been restored, too. After some time, however, I noticed that it was losing battery very quickly. I checked the usual culprits and found that, indeed, the phone was using lots of mobile data. Turning off mobile data showed that the phone had a healthy battery.
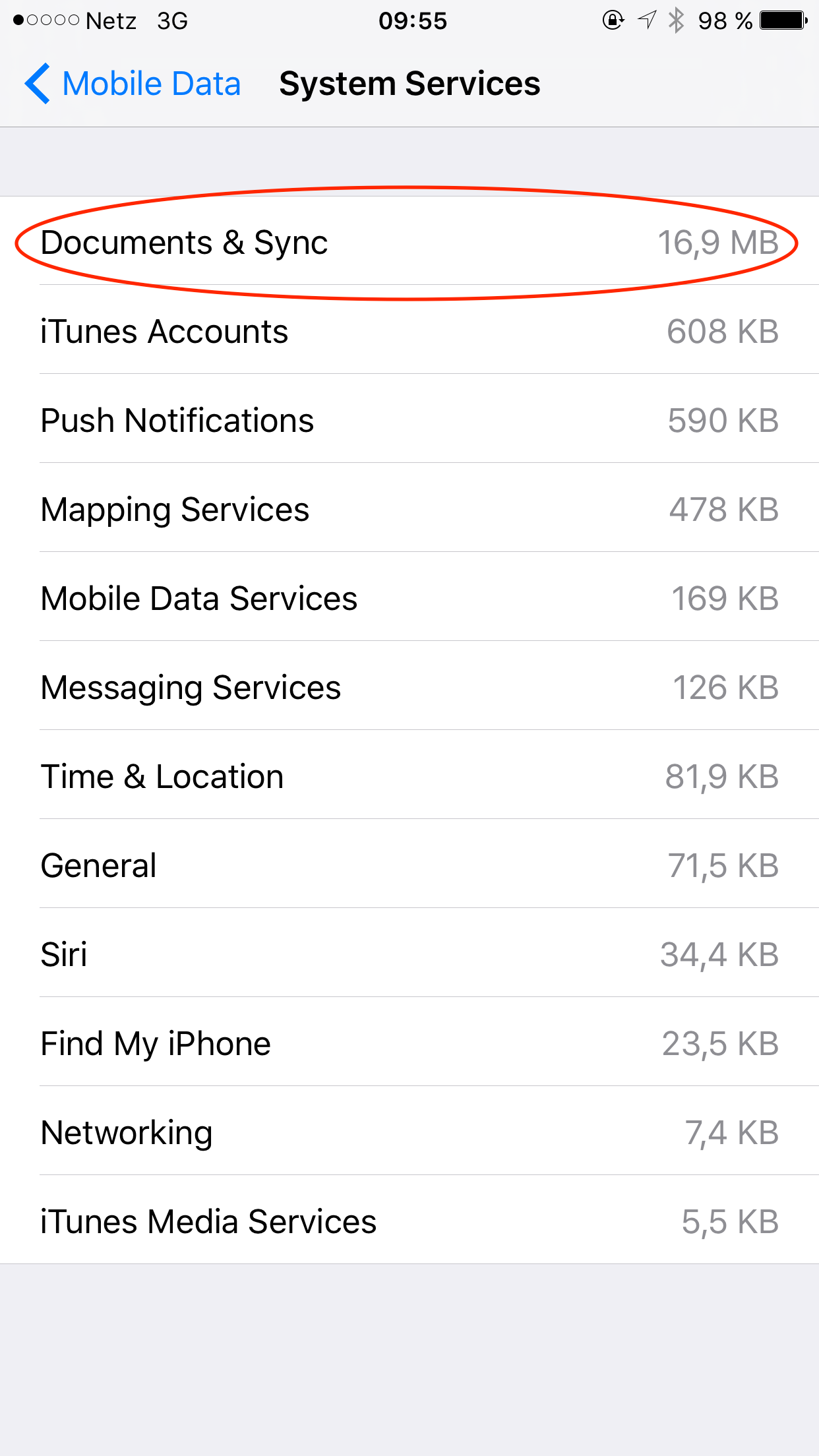
But the mobile data issue didn’t go away. I deactivated WiFi support and other known possibly problematic features. Eventually I deactivated iCloud documents and iCloud altogether, but the problem persisted: the phone was using up lots of mobile data — and almost all of it in “System Services > Documents & Sync”. I could almost watch it use up my mobile data quota as it was sucking (or pushing?) about one Megabyte for every two minutes or so.
I called Apple Service and they told me to reset my iPhone completely and set it up as a new one. Since I didn’t find time to do that immediately, I simply switched off mobile data for the time being and activated it only from time to time when I needed mobile internet access. At some point this started to annoy me sufficiently so that I wanted to tackle the problem again and so I activated mobile data again yesterday just to find that the problem had miraculously disappeared. With the same settings as before, the iPhone was now behaving as it should using less than 1 Megabyte in 3 hours or so for “Documents & Sync”.
I can only speculate as to the origin of the problem and why it has solved itself. Perhaps the iCloud sync was somehow confused by the phone swap and somehow ended up in an endless loop of syncing the phone to the cloud and vice versa and again? And then at some point a cleanup daemon deleted old sync files on Apple’s servers so that it now works again? I will probably never now.
The lesson I learned from this incident is, however, that it’s not always worth trying to solve a (minor) problem immediately since it may solve itself as time passes. 🙂
owncloud on the Raspberry B+/2B: a 10x performance boost
Since more than two years now I was using my Raspberry Pi B+ as an owncloud-Server. Triggered by the various spy scandals and fascinated by the possibilities of this small and efficient computer, I wanted to see if it is possible to use comfortable cloud services while also having control over my data (it is). I enjoy my private owncloud for keeping notes up-to-date across my devices, but also for sharing pictures and files with family and friends. The client connection was always pretty fast and since I recently upgraded my home internet connection to V-DSL with 100 MBit/s (upload 10 MBit/s), upload speed is no longer a big issue. However, the PHP web interface was always relatively slow on my old Raspy model B+ and so I invested in a new Raspy 2 to see if that would improve the speed. This new Raspy features a four-core ARM Cortex–A7 processor @ 900 MHz with 1 GB of fast RAM: Quite an improvement over my Raspy B+ with a single-core 700 MHz processor with 512 MB of RAM. I was hoping for a significant boost for the owncloud performance since the Apache server forks into many processes even for a single connection and should thus be able to make use of the new Raspyb’s multi-core CPU. And I was not disappointed!
(more…)
Install Python with two lines of code
There are long discussions about which is the best or “right” way to install Python, but in case you just want to use it, here are the only two lines of code you need to enter in a terminal on your Mac to install a working Python environment with the latest Python 3.x including the packages numpy, scipy, astropy and iPython (among many other things).
- Install Homebrew:
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
- Install the latest Python 3.x and relevant packages:
brew install python3
And that’s it. You can now start using Python by typing
ipython3
This will launch an interactive Python shell (which allows you to use tab-completion among many other neat things).
An analysis of astro-ph submit times
Recently I submitted another paper to astro-ph and I wanted to play the “first” game and try to get my paper on top of the daily listing. Now, it is well documented that the deadline for the daily submissions is 16.00 EST meaning that if you submit just after that deadline you’re paper is likely to appear on top of the next day’s mailing. (NB: the announcement is inverse on the web page)
But how likely do you get your paper on top if you submit right in time? For the above mentioned paper I had prepared everything before hand. This took a bit of time since arxiv.org didn’t accept a
\maketitle
after the abstract but only spewed out weird errors about lines that aren’t ending etc. So I had prepared everything, even submitted the paper and un-submitted it again.
Then, at 20.59.59 GMT and a split second I hit the submit button. It took more than three minutes for the server to handle this request. Still, I was quite amazed that the paper appeared only as #6 (#19 if counting also the cross-lists) from the bottom of the webpage (i.e. top of presumably more important mailing), despite having been registered by the server at 21.00.04 GMT. So I used my much-loved bash tools curl, awk and grep and extracted the submission times of all astro-ph submissions this year until October and found this:
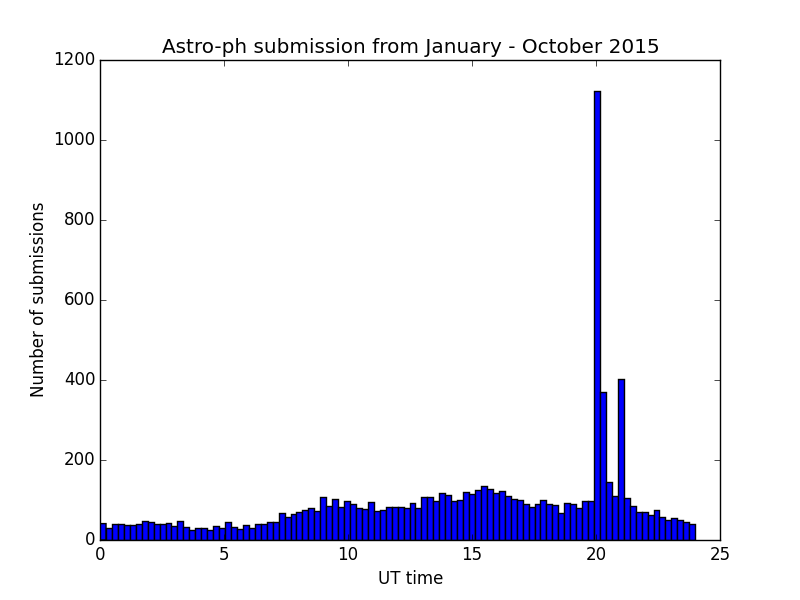
There is a clear spike at 20.00 UT (which is 16.00 EDT = UTC-4) and a smaller one at 21.00 UT (corresponding to 16.00 EST = UTC-5) — most of the year so far has had (Northern hemisphere) summer time. I don’t have an explanation for the smaller and wider peaks at about 9.00 and 16.00 UT. Now we can also zoom in to the region around 20 / 21:
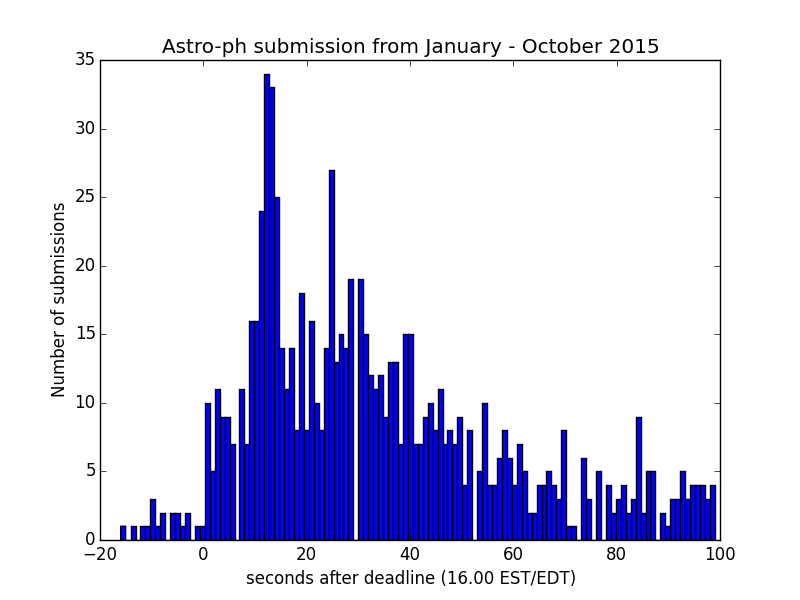
We see that the peak submission time (which is when the submission is registered by the server) is at about 12 seconds after the deadline. Going back to my case — submitting right at the deadline, registered 4 seconds after the deadline (despite server only replying 3 minutes later) — we can ask: what are the chances of getting on top if you submit within 4 seconds? Over these 10 months (ca. 200 submission days), there have been 26 submissions in this timeframe, i.e. your chances of getting on top if submitting so close in time should be almost 100%. It just so turns out, however, that on the particular day when I submitted, there were five papers submitted even closer to the deadline. Tough luck. 😉 Hopefully, however, this will play less of a role in the future as more and more people read their daily astro-ph through voxcharta or similar services where the announcement order is either randomized or sorted according to your preferences.